Measurement science
Advertising measurement method selector
Most measurement mistakes begin before the analysis starts. A team asks one question, buys a method built for another question, and then treats the output as if it settles the decision.
A common version looks harmless: the sales report says revenue rose after launch, the attribution report gives one channel most of the credit, the brand study shows a small recall gain, and the budget owner asks what to do next. Each signal may be useful. None of them can answer every question.
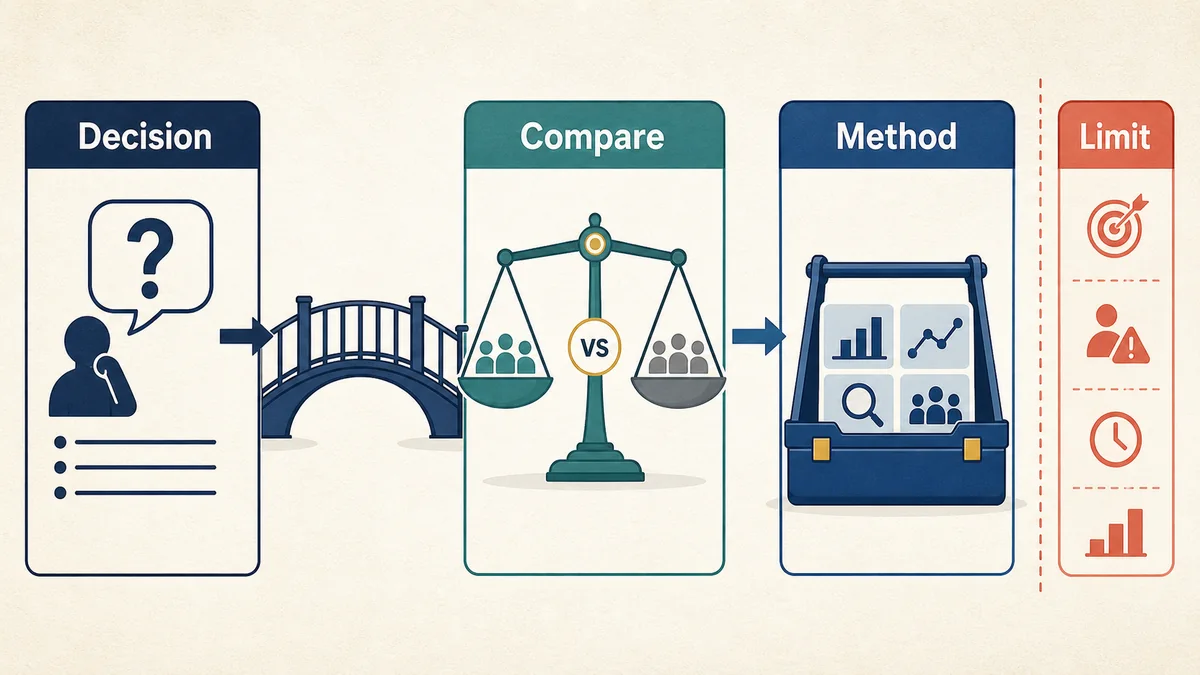
This selector is a practical way to slow that down. Start with the decision, name the counterfactual, choose the method that can answer it, and keep every result inside the boundary of what the design can support. In plain language, the counterfactual is the comparison that says what probably would have happened if the campaign had not run.

Start with the decision
Do not begin with "we need MMM" or "we need a lift test." Begin with the sentence the decision owner will use after the readout. A method that is strong for one sentence can be weak or misleading for another.
Before a vendor brief, analytics request, or internal readout, write a short selection ticket. It keeps the method tied to the business choice instead of letting the available dashboard define the question.
| Selection ticket field | Write this before choosing the method | Why it prevents overclaiming |
|---|---|---|
| Decision owner | The person or team that will change a budget, bid, creative plan, launch plan, or renewal language. | Prevents measurement work from becoming an interesting report with no practical action. |
| Action under review | Scale, hold, pause, renew, shift mix, change creative, fix tracking, or run a stronger test. | Different actions need different confidence. A diagnostic may be enough for repair, but not for scale. |
| Counterfactual | The comparison that represents what would probably have happened without the campaign or change. | Forces the team to separate after-launch movement from incremental impact. |
| Primary outcome | One outcome tied to the decision, such as incremental conversions, qualified leads, revenue, recall, or reach quality. | Stops the readout from switching to whichever metric looks best after results are visible. |
| Minimum useful effect | The smallest change that would justify the action after cost, risk, timing, and uncertainty are considered. | Turns a "positive" result into a decision threshold instead of a celebration of any upward movement. |
| Decision deadline | The date when the evidence must be ready for planning, renewal, launch, or closeout. | Clarifies whether a quick diagnostic, a live holdout, or a longer modeling plan is realistic. |
| Decision question | Usually stronger method | What it still cannot prove alone |
|---|---|---|
| Should next quarter's budget move between channels? | MMM calibrated with credible experiments where available. | That every channel estimate is causally identified or stable across future conditions. |
| Did this campaign create incremental conversions? | Randomized conversion lift test with protected holdout and a fixed outcome window. | That the same lift will hold for a different audience, creative, season, or bid strategy. |
| Did a market-level launch or retail push work? | Geo, store, or matched-market test with balanced pre-period trends. | That one strong region represents the national average. |
| Did the campaign change awareness or consideration? | Brand study with comparable exposed and control respondents. | That survey movement caused profitable sales movement. |
| Which impressions were more likely to be noticed? | Attention measurement used as an exposure-quality diagnostic. | That attention is the same thing as incremental business value. |
| Which touchpoints appeared in observed paths? | Attribution or path reporting, labeled as descriptive. | That the last or weighted touch caused the conversion. |
The method matrix
MMMBest for budget planning when spend, outcomes, prices, seasonality, distribution, and other business drivers can be modeled over time. It needs transparent controls, priors, response curves, uncertainty, and calibration. Predictive fit is not enough for causal confidence.
Randomized lift testBest when assignment can be controlled and treatment and holdout groups can be kept meaningfully separate. The readout should name the estimand, exposure compliance, primary outcome, confidence or credible interval, and generalization limits.
Geo or store testBest when treatment is applied by location rather than person. The core check is whether treatment and control areas had similar pre-period levels and trends before the campaign changed anything.
Brand studyBest for directional perception outcomes such as awareness, recall, favorability, and consideration. It becomes weaker when response bias, small samples, proxy outcomes, and sales claims are hidden behind a single lift number.
Attention measurementBest for diagnosing exposure quality across placements, formats, creative, and environments. It is useful when paired with a decision rule, but it should not be treated as a universal currency for business outcomes.
Attribution reportingBest for describing observed paths, handoffs, and operational tracking gaps. It can guide QA and tactics, but it should not be used as the main proof that media caused demand.
Minimum disclosure checklist
| Every serious report should state | Why it matters |
|---|---|
| The decision the result is meant to inform. | A method is only useful if it changes a real planning, buying, creative, or product choice. |
| The counterfactual being estimated. | Readers need to know what the campaign is being compared against. |
| The unit of analysis and unit of assignment. | User, household, market, store, and time-window designs have different leakage risks. |
| The primary outcome and readout rule. | Prevents a positive-looking secondary metric from replacing the planned decision threshold. |
| Important exclusions, model assumptions, and uncertainty. | Lets readers distinguish a robust result from a fragile point estimate. |
| Where the result should not be generalized. | Keeps a narrow but useful finding from becoming an inflated planning claim. |
How methods work together
The strongest measurement programs do not force every question through one tool. Attribution can reveal broken tagging. Lift tests can calibrate causal expectations. MMM can turn multiple signals into planning ranges. Brand studies can explain whether a campaign changed memory or perception before sales data is mature.
The discipline is to keep each signal in its lane. A brand lift study should not become proof of profitable sales lift. A path report should not become incrementality proof. An MMM should not hide the experiment evidence that would make its causal claims stronger or weaker.
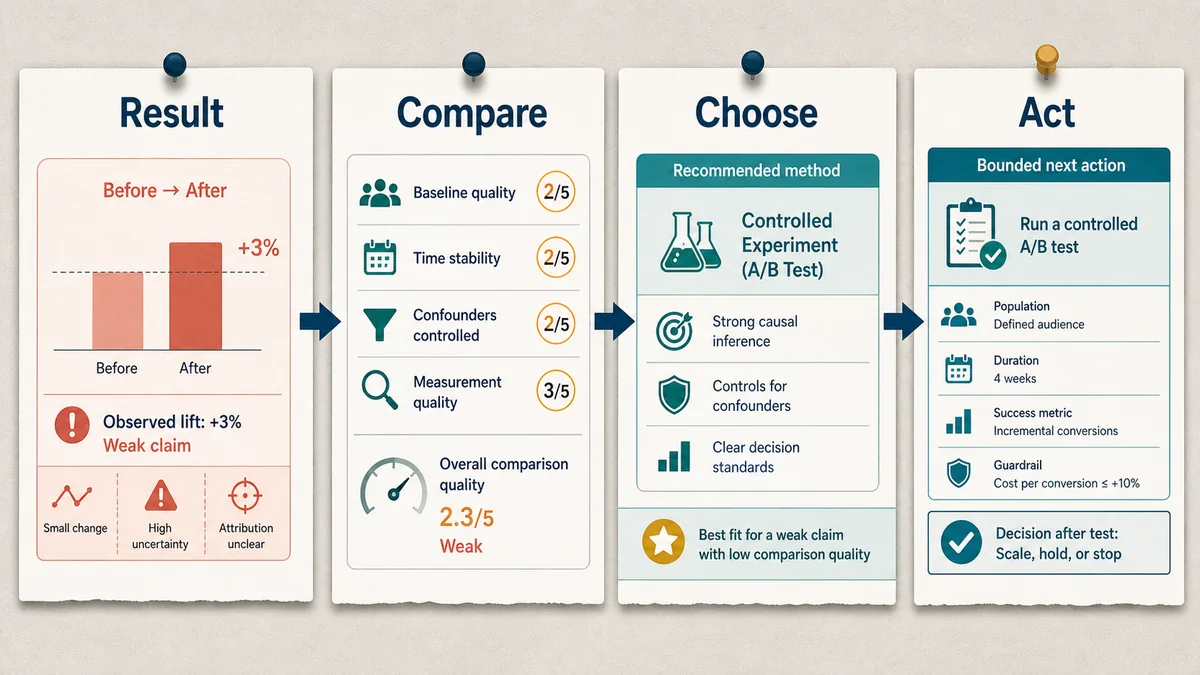
Worked example: before-after lift is not enough
Suppose a campaign launches in June and qualified leads rise by 3% compared with May. That is an observed change, not yet a causal result. A 3% increase might be useful, but it could also come from seasonality, a pricing change, a sales-team follow-up push, a landing-page fix, or customers who were already going to convert.
The method choice depends on the action. If the team only needs to debug tracking or qualify the next creative test, a descriptive readout may be enough. If the team wants to scale the campaign budget, the comparison has to get stronger.
| Observed situation | Do not say yet | Better next step | Decision language after the step |
|---|---|---|---|
| Leads rose 3% after launch, but no control group exists. | "The campaign drove a 3% lift." | Check baseline stability, marketing calendar, sales follow-up, lead quality, and tracking changes. | "Leads increased after launch, but causality is not established." |
| The comparison period is seasonally weak or operationally different. | "The new media mix is outperforming the old mix." | Use a matched period, geo comparison, store comparison, or model with explicit controls. | "The result is directional until comparison quality improves." |
| The campaign can protect a holdout or randomize eligibility. | "Attribution proves the winner." | Run a randomized lift test with one primary outcome and a fixed readout window. | "The test estimates incremental impact for this audience, window, and treatment." |
| The action is a broad budget shift across channels. | "One campaign test settles next quarter's mix." | Use experiments to calibrate MMM or a planning model that includes non-media drivers. | "Budget movement is supported within the model range and calibration limits." |
Fast diagnostic
- If the report answers "what happened after launch," ask for the comparison that shows what would have happened anyway.
- If the report answers "who converted," ask whether those people were already more likely to convert before exposure.
- If the report answers "which channel ranked highest," ask how uncertainty and calibration changed the ranking.
- If the report answers "what people remembered," ask whether the survey population is comparable and whether the outcome matches the decision.
- If the report answers "which placement got attention," ask what business decision attention is supposed to improve.
Takeaway
Choose the method after the decision is clear, not after the dashboard is available. A weaker method honestly labeled is more useful than a stronger-looking method used outside its lane.
Open the broader method route.
Use these routes when method choice leads into a campaign readout, a stronger test plan, or a worked failure mode.